The Metal Behind the Magic

Most people meet artificial intelligence through surfaces.
A product demo on stage, a robot walking across a factory floor, a chat window flowing with text.
But the real story of AI is written in floor plans, switchgear, cooling loops, and balance sheets.
The systems that matter most are rarely photographed: dense training clusters drawing hundreds of megawatts, network fabrics tuned to move gradients rather than web pages, and liquid cooling plants that look more like industrial utilities than anything in consumer tech.
This is the quiet part of the revolution.
If you follow the money, the engineering effort, and the planning risk, you end up not at the robot demo, but at the training rack.
The hidden layer
A large-scale AI training cluster is sometimes described as “just a data center,” but its physics and economics are different from conventional computing.
Instead of CPU-heavy racks at 5–10 kilowatts each, AI clusters routinely push rack densities above 50–70 kilowatts, forcing a shift from traditional air cooling to direct-to-chip or immersion liquid systems.
Power draw scales accordingly.
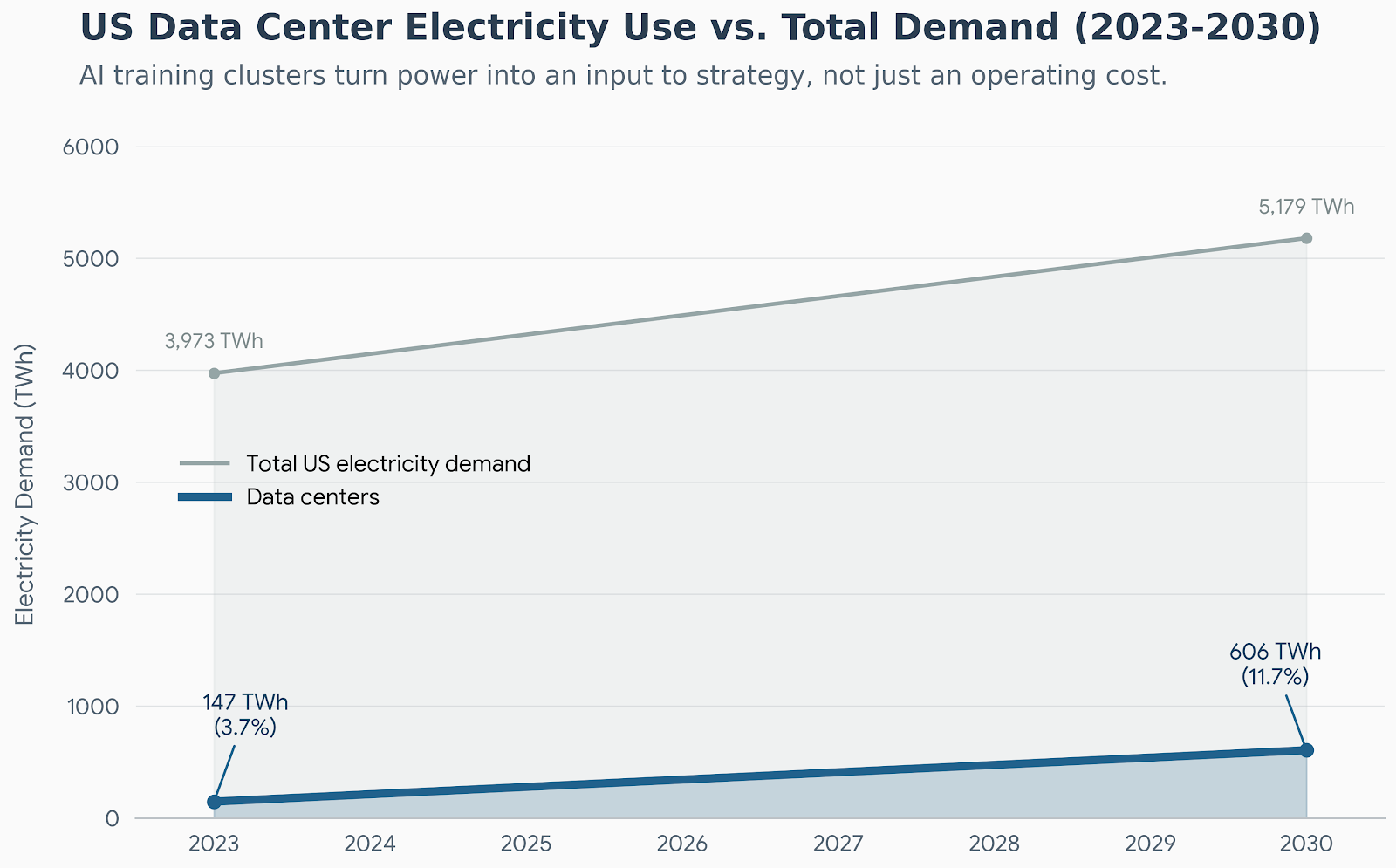
Recent analyses of AI-focused facilities describe single training campuses needing on the order of 100–300 megawatts per site, with multi-building complexes approaching the load of a small city, pushing grid connections, substation build-outs, and long-term power contracts to the center of the design problem.
Cooling becomes an engineering discipline in its own right.
Operators are moving toward closed-loop liquid systems and immersion tanks to handle the heat flux from tightly packed accelerators, targeting power usage effectiveness (PUE) levels near 1.1 while managing water use and leak risk.
Networking is the third pillar.
The specialized fabrics that connect thousands of GPUs or TPUs—using InfiniBand or high-speed Ethernet spine–leaf topologies—can represent capex line items comparable to the compute hardware itself, because any bottleneck in all-reduce communication stalls the entire training job.
When you zoom out, a training cluster is not a room full of clever chips; it is a coordinated machine for turning electricity and capital expenditure into gradient updates under strict thermal and networking constraints.
That is the layer that determines whether a model can be trained at all, let alone iterated quickly.
While the mainstream media was obsessed with panel gaps on the Cybertruck, Elon Musk was quietly building something else in Memphis, Tennessee.
They call it "Project Colossus."
It is the largest AI training cluster in the world—powered by 100,000 state-of-the-art GPUs.
Its purpose? To train the brain of the next generation of humanoid robots.
This is the "machine behind the machine."
Project Colossus is training robots to learn exponentially faster than humans ever could. It is the reason we are about to see a "ChatGPT moment" for physical reality.
You cannot buy stock in Project Colossus directly. It is locked inside a private company.
But you CAN buy the public company that supplies the "sensory organs" for the robots it trains.
This stock is the bridge between the digital super-intelligence in Memphis and the physical robots walking into our factories.
And right now, it is trading for peanuts compared to the big tech giants.
Why compute concentration changes industrial timelines
AI training is latency-insensitive but throughput-hungry.
A model that once took months to train on a modest cluster can be retrained in days on a facility with tens of thousands of accelerators, collapsing the learning cycle and allowing more architectural experiments per unit time.
That capacity is far from evenly distributed.
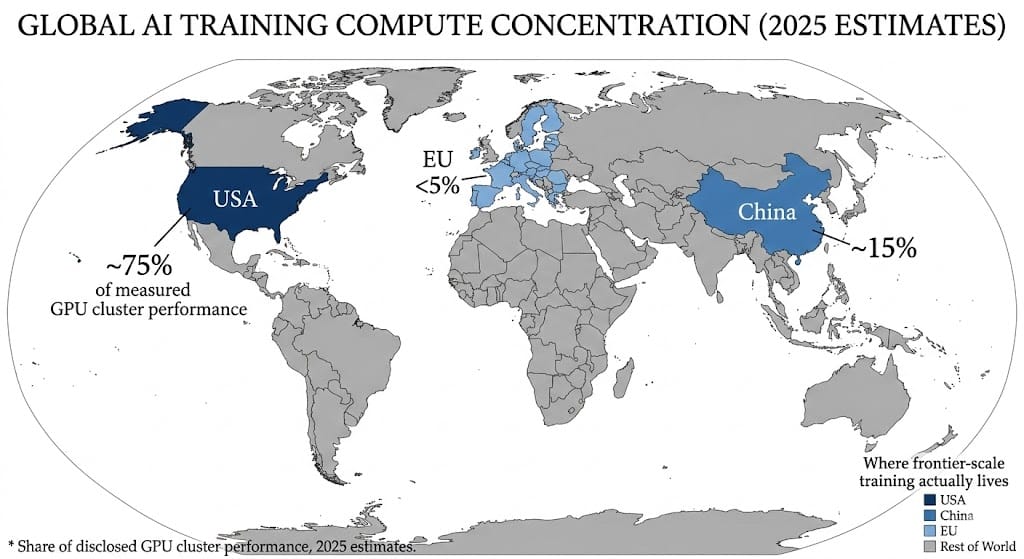
Recent measurements of disclosed GPU cluster performance estimate that, as of mid‑2025, the United States hosts roughly three‑quarters of global AI cluster compute power, with China at about 15 percent and the European Union under 5 percent.
The imbalance is not just geopolitical trivia; it changes who can realistically run frontier-scale experiments.
A country or company with a dominant share of usable training compute can iterate on model architectures, data curation, and safety techniques faster than others, even if everyone has access to similar algorithms.
At the same time, data-center analysts note that the biggest constraint on additional AI capacity is often not chip supply but deliverable power and cooling readiness on a realistic construction timeline.
Power-constrained growth means that whoever locked in land, substations, and grid contracts early effectively pulled their learning timelines forward relative to latecomers.
Training clusters can live far from end users—latency is less critical when you are updating weights rather than serving real-time responses—so operators can chase cheap or low‑carbon power, further reinforcing advantages for regions with favorable energy infrastructure.
The result is a world where learning speed is set less by software genius and more by long-run capital planning.
What the Public Sees vs. What Actually Drives AI
| What the public sees | What actually drives AI |
|---|---|
| Slick robot demos and humanoids on stage | Months of prior training on GPU superclusters drawing hundreds of megawatts, plus edge–cloud coordination to make latency acceptable.iweekly+1 |
| Viral chatbots and productivity apps | Dense training runs on specialized accelerators, followed by cost-optimized inference clusters and careful GPU scheduling to manage energy and capex.mdpi+1 |
| “AI rankings” by country based on startups or patents | Underlying share of global GPU cluster performance, where the U.S. currently holds about 74.5 percent and China roughly 14 percent.epoch |
| Talk of “AI moats” as data or brand | Long-term power contracts, liquid-cooling retrofits, network fabrics, and the ability to spend billions on capex without breaking the balance sheet.iweekly+2 |
| Factory-floor robots as evidence of national capability | Upstream supply of accelerators, optics, sensors, edge-compute modules, and the connectivity that keeps fleets synchronized.arxiv+2 |
The gap between surface and structure is wide.
Most of the leverage sits in the right-hand column.
Robotics as downstream beneficiary
Robots are often treated as the vanguard of AI, but in practice they sit downstream of training infrastructure.
Embodied systems depend on policies and perception models that were refined in large-scale training environments long before they ever reach a factory or warehouse.
Work on edge and cloud robotics architectures shows why.
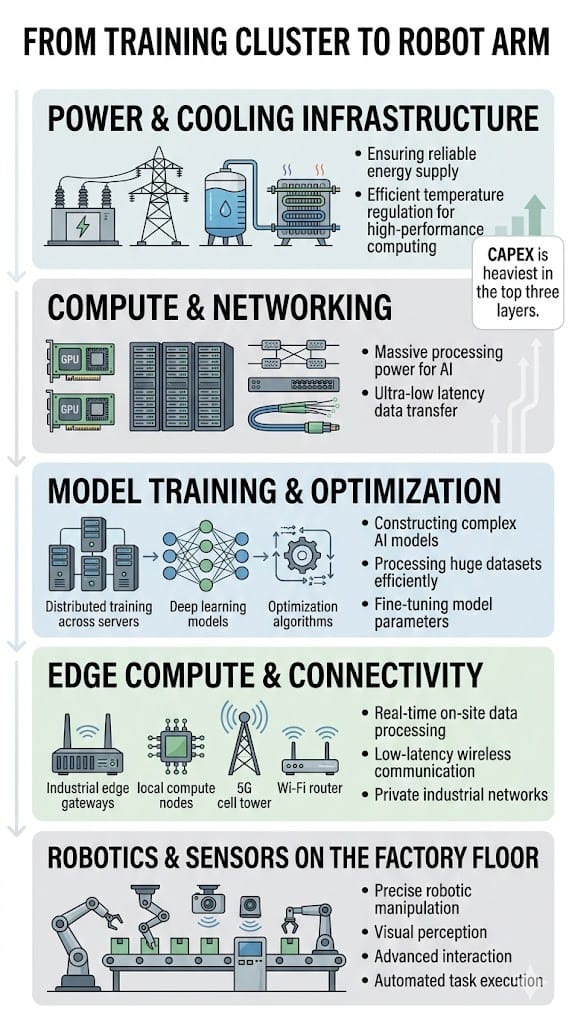
Surveys of edge computing for robotics describe robots offloading vision and planning tasks to nearby or remote compute nodes equipped with GPUs, NPUs, and other accelerators, with the edge layer acting as an intermediary between robot fleets and central cloud training clusters.
This architecture assumes that the hard work of representation learning, simulation, and large-model training has been completed on powerful clusters, and that what flows to robots are distilled models or task-specific fine-tunes.
Industry briefings on “physical AI” stacks—from component makers to systems integrators—reinforce the picture: the robotics boom is constrained first by model quality and connectivity, both products of upstream training muscle.
In this view, the robot demo is a late-stage integration milestone.
The real bottleneck is still in the data center.
The ecosystem effect
Building and operating AI training clusters pulls a long chain of suppliers into its orbit.
Semiconductor manufacturers at the leading edge continue to dominate headlines, but the dependency graph runs through optics, power electronics, and niche industrial components.
On the sensing side, robotics and industrial automation rely on increasingly sophisticated cameras, lidar, and motion sensors that embed edge AI directly in the device.
For example, recent motion sensors for industrial environments integrate in‑sensor machine learning to filter and classify events locally, reducing the bandwidth and latency burden on upstream systems.
Edge computing surveys in robotics describe heterogeneous modules equipped with GPU, NPU, TPU, FPGA, and other accelerators, sitting near the robots to preprocess sensor data, generate control instructions, and synchronize with cloud models.
This creates demand for ruggedized compute, specialized connectors, and reliable networking compatible with factory conditions and 5G or Wi‑Fi 6 backhaul.
Even apparently mundane components—power distribution units, liquid-cooling manifolds, leak-detection systems—become strategic as rack densities and energy elasticity rise.
Studies of AI data-center energy use emphasize that the overall facility footprint is a product of both IT load and an “infrastructure multiplier” that depends on cooling, power conversion, and distribution efficiency.
Risk lens
The same forces that create leverage also create fragility.
When three-quarters of measured GPU cluster performance is concentrated in a single country and heavily skewed toward a handful of hyperscalers, geopolitical shocks, export controls, or supply-chain disruptions can ripple quickly through global model progress.
Capex cycles are another source of risk.
Industry reports estimate that hyperscalers collectively spent on the order of hundreds of billions of dollars on AI-related data-center and accelerator investments in 2025, a pace that assumes sustained demand for training and inference services that may not materialize uniformly across sectors.
Power and infrastructure constraints can also delay returns.
Data-center operators note that in many regions the binding limit on new AI capacity is not land or building shells but the ability to secure and deliver sufficient power, build out liquid-cooling systems, and deploy high-performance network fabrics on credible timelines.
Energy and environmental dynamics add further uncertainty.
Scenario analyses of data-center energy to 2030 introduce the concept of “AI energy elasticity,” highlighting that in the short term, total power consumption can remain highly sensitive to AI workload growth because efficiency gains in hardware and cooling are offset by rising model sizes and adoption.
Finally, deployment risk remains real.
Industrial users may move more slowly than the hype cycle suggests, constrained by integration costs, safety requirements, and legacy systems, even as training clusters continue to scale ahead of proven, durable revenue streams.
For investors and policymakers, the question is not whether AI clusters are powerful, but whether their economics remain resilient across energy markets, credit cycles, and regulatory regimes.

Tech Expert Who Called NVIDIA in 2016 and Tesla in 2018 Exposes:“NVIDIA CEO Makes
Major Prediction”
Brownstone Research
AI’s visible moments will always happen on screens and factory floors.
A robot stacking boxes or an assistant drafting emails is easier to film than a substation or a cold‑plate manifold.
But the center of gravity has already shifted.
The real leverage now lies in who can plan, finance, and run dense training clusters under tight thermal and power constraints, and then propagate that capability outward through edge infrastructure, sensors, and robotics.
Revolutions, in other words, begin in server racks—under fluorescent light, next to cooling loops and switchgear.
By the time they reach the production line, most of the important capital-structure decisions have already been made.
—
Claire West